The Document Attachments were stored in our AX 2012 database, and were occupying several hundred GBs. As part of the migration to D365FO we had to export these files in bulk. The most efficient way is to run the batch task in parallel. But this data is tilted in a way that if you would group the tasks based on their creation date, it the first tasks would barely have any records to process while the last ones would go on forever. The solution for this is called data histogram equalization.
It would be a big challenge to code this in X++, but SQL Server has a function for doing this exactly: NTILE.
The following direct query is able to process the data histogram, and then return 10 buckets of Record Identifier ranges of roughly equal size:
WITH documents (Bucket, RecId)
AS (
SELECT NTILE(10) OVER( ORDER BY DocuRef.RecId) AS Bucket
,DocuRef.RECID
FROM docuRef
INNER JOIN docuType
ON (docuType.dataAreaId = docuRef.RefCompanyId OR DOCUREF.REFCOMPANYID = '')
AND docuType.TypeId = docuRef.TypeId
INNER JOIN docuValue
ON docuValue.RecId = docuRef.ValueRecId
WHERE docuType.TypeGroup = 1 -- DocuTypeGroup::File
AND docuType.FilePlace = 0 -- DocuFilePlace::Archive
AND docuType.ArchivePath <> ''
AND docuValue.Path = ''
)
SELECT Bucket
,count(*) AS Count
,(SELECT MIN(RecId) FROM documents D WHERE D.Bucket = documents.Bucket) AS RecId_From
,(SELECT MAX(RecId) FROM documents D WHERE D.Bucket = documents.Bucket) AS RecId_To
FROM documents
GROUP BY BucketHere are the results for spawning 10 batch job tasks to do parallel execution based on the RecId surrogate key index, with ~57230 rows in each bucket. This allows you to evenly distribute the load for data processing in parallel.
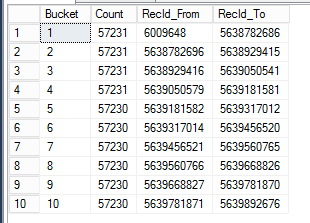
If we would export our document attachments sequentially, it would take roughly 40 hours total. By utilizing the data histogram equalization we could get it down to be under 3 hours. That is amazing!
It is a great way to split ranges of data for parallel processing, to keep in mind for the future.
You can learn more about the functionality here:
https://www.sqlitetutorial.net/sqlite-window-functions/sqlite-ntile/
Leave A Comment